GraalVM NativeImage 逆向还原
Java代码还原与保护是一个老生常谈的问题,由于Java类文件的采取字节码格式保存,包含了许多元信息,所以可以很容易还原成原始代码。为了保护Java代码,业界采用了许多手段,比如混淆、字节码加密、JNI保护等等,但是无论哪种方法,都仍存在破解的方法和途径。
二进制编译,一直被认为是代码保护较为有效的一种方法,Java的二进制编译被撑为AOT技术(Ahead of Time),即提前编译。
但是由于Java语言的动态特性,二进制编译需要处理反射、动态代理、JNI加载等问题,存在许多的困难,所以很长时间一来,Java的AOT编译方面一直缺乏一个成熟可靠、适应性强并且可大范围应用于生产环境的工具。(曾经有一个叫做ExcellisorJET,如今似乎已停止维护)
2019年5月,Oracle推出了GraalVM 19.0,一个多语言支持的虚拟机,19.0是它第一个面向生产环境的版本。GraalVM中提供了一个NativeImage工具,能够实现Java程序的AOT编译。经过几年的发展,目前NativeImage已经十分成熟,SpringBoot 3.0已经可以使用它将整个SpringBoot工程编译生成一个可执行文件,编译后的文件,启动速度快,内存占用低,具有非常好的效果。
那么,对于已经迎来二进制编译时代的Java程序来说,其代码是否仍是像字节码时代一样容易被逆向还原呢,NativeImage编译的二进制文件又有哪些特点,二进制编译的强度是否足够用来保护重要的代码?
为了探讨上述问题,笔者近期编写了一个NativeImage分析工具,已经能达到一定的逆向还原效果。
项目地址
https://github.com/vlinx-io/NativeImageAnalyzer
生成NativeImage
首先我们需要生成一个NativeImage,NativeImage来自于GraalVM,访问https://www.graalvm.org/ 下载Java 17版本,下载完成后设置好环境变量,GraalVM中同样包含了一个JDK,因此可以直接使用它执行Java命令.
添加$GRAALVM_HOME/bin到环境变量,之后执行
gu install native-image
编写一个简单Java程序
编写一个简单的Java程序,例如
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
编译并运行上述Java程序
javac Hello.java
java -cp . Hello
可以得到程序输出
Hello World!
编译环境准备
如果是Windows用户需要提前安装好Visual Studio, 如果是Linux与macOS用户,需要提前安装好gcc与clang等工具。
Windows用户在执行native-image命令之前,需要先设置好Visual Studio的环境变量,可以通过下述命令设置
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
如果Visual Studio的安装路径与版本不同,请自行调整相关路径信息。
使用native-image进行编译
现在使用native-image命令将上面这个Java程序编译成二进制文件, native-image命令的格式与java命令格式一致,同样有-cp, -jar这些参数,如何使用java命令来执行程序,就使用同样的方式进行二进制编译,只不过命令从java换成了native-image。执行命令如下
native-image -cp . Hello
经过一段时间的编译,期间可能会占用较多的CPU与内存,可以得到一个编译后的二进制文件,输出文件名默认为主类名的小写,此处为hello,如果是Windows下则为hello.exe,使用file命令来查看这个文件的类型,可以看到这确实是个二进制文件了
file hello
hello: Mach-O 64-bit executable x86_64
执行这个文件,其输出与前面使用java -cp . Hello的结果一致
Hello World!
分析NativeImage
使用IDA进行分析
使用IDA打开上面步骤编译的hello,点击Exports查看符号表,可以看到个svm_code_section符号,其地址就是Java Main函数的入口地址
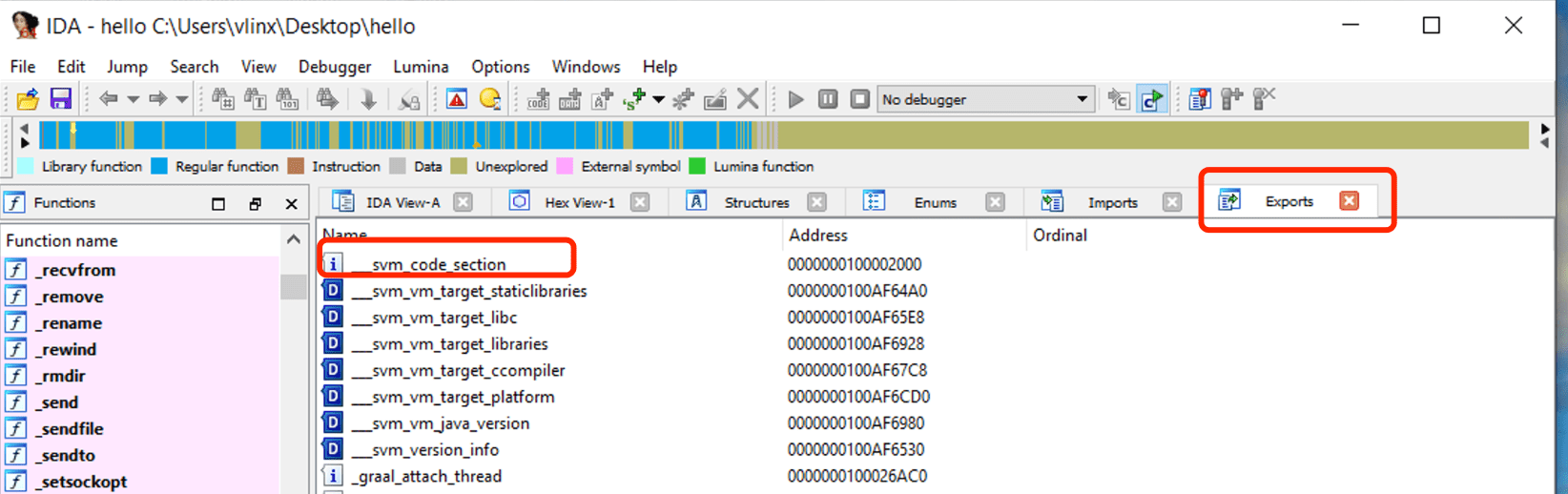
定位到这个地址,查看汇编代码
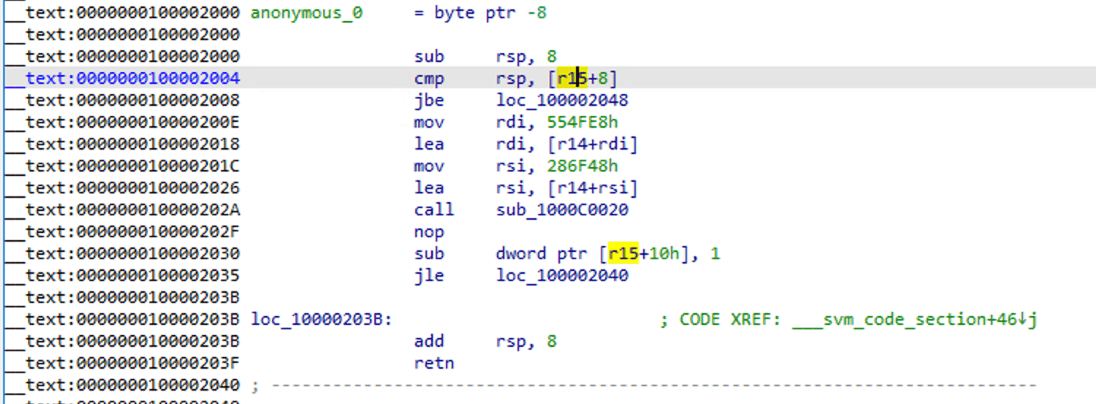
可以看到已经是标准的汇编函数的样子了,使用F5进行反编译
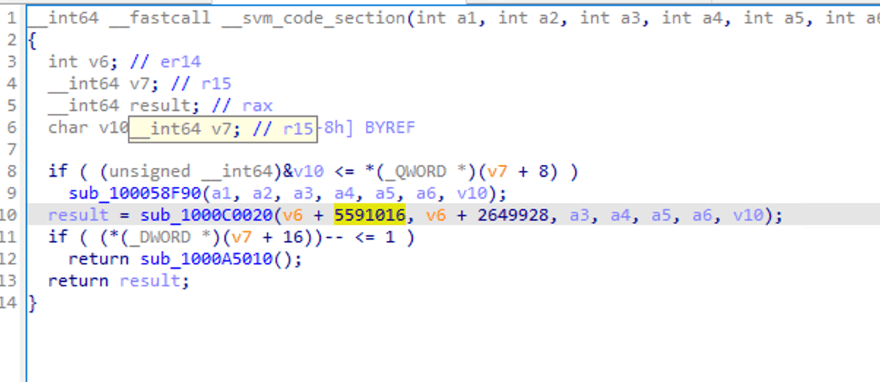
可以看到进行了一些函数调用 ,传递了一些参数,但是不容易看出逻辑。
我们双击sub_1000C0020,看看调用函数的内部,IDA提示分析失败
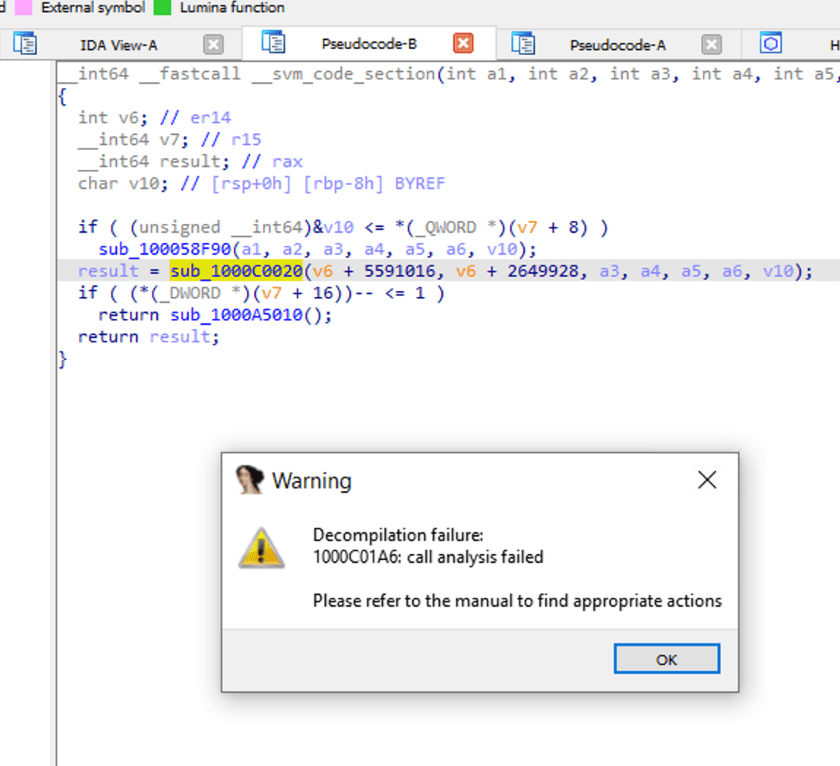
NativeImage 反编译的逻辑
因为NativeImage的编译是基于JVM的编译,也可以理解为给二进码代码套了一层VM保护,所以IDA这类工具,在缺乏相应信息以及针对性处理措施的情况下,是无法很好的对其进行逆向还原的。
但是不论何种形式,以字节码的形式,还是以二进制的形式,JVM的执行的一些基本要素必然是存在的,例如类的信息,字段的信息,函数的调用与参数的传递等,基于这个思路,笔者编写的分析工具已能达到一定的还原效果,并且再加以完善的话,有能力达到足够高级别的还原度。
使用NativeImageAnalyzer进行分析
访问https://github.com/vlinx-io/NativeImageAnalyzer下载NativeImageAnalyzer
执行下述命令进行逆向分析,目前仅分析主类的Main函数
native-image-analyzer hello
得到输出如下
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
我们再来看下原来的代码
public static void main(String[] args){
System.out.println("Hello World!");
}
我们现在来看下System.out的定义
public static final PrintStream out = null;
可以看到System类的out变量是一个PrintStream类型的变量,并且是一个静态变量,NativeImage在编译的时候直接将这个类的实例编译到一个叫做Heap的区域,二进制代码直接从Heap区域获取这个类的实例进行调用,我们再来看下还原后的代码
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
这里的java.io.PrintStream@0x554fe8 就是从Heap区域中读出的java.io.PrintStream的实例变量,其在内存中的地址为0x554fe8
我们再来看下java.io.PrintStream.writeln 函数的定义
private void writeln(String s) {
......
}
我们这里可以看到writelin函数中有一个String类型的参数,而还原的代码中为什么传递了三个参数了,首先writeln是一个类成员方法,只默认隐藏了一个this变量指向调用者,即传递的第一个参数java.io.PrintStream@0x554fe8,至于第三个参数rcx,是因为在进行汇编代码分析的过程中判断这个函数调用了三个参数,但实际上看定义我们知道这个函数实只调用两个参数,这也是本工具后续需要改进的地方。
一个复杂点的程序
我们接下来分析一个复杂点的程序,比如计算一个Fibonacci数列,代码如下
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
编译并执行
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
使用NativeImageAnalyzer还原后获得代码如下
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
把还原后的代码与原代码比较下
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
对应的是
int count = Integer.parseInt(args[0]);
rdi是用来传递函数的第一个参数的寄存器,如果在Windows下则是rdx,rdi=rdi[0]即对应了args[0],之后调用java.lang.Integer.parseInt解析获得一个int数值,然后将返回值赋值给一个栈上变量sp_0x44
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
对应的是
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
我们在Java代码中非常简单的字符串相加操作,在Java背后实际转为了StringConcatHelper.mix,StringConcatHelper.prepend,StringConcatHelper.newString三个函数的调用,其中StringConcatHelper.mix计算字符串相加后的长度,StringConcatHelper.prepend用来将具体承载字符串内容的byte[]数组组合在一起,StringConcatHelper.newString则通过byte[]数组生成一个新的String对象
我们在上面这段代码看到了两个类型的变量名称,sp_0x18与tlab_0,sp_开头的变量,表示这是一个在栈上分配的变量,tlab_开头的变量表示在Thread Local Allocation Buffers上分配的变量,这里仅是对这两种变量名称的由来做一个说明,在还原代码中这两类变量没有区别,关于Thread Local Allocation Buffers的相关资料,大家可以自行查找。
我们这里给tlab_0赋值为Class{[B}_1, Class{[B}_1的含义是这是byte[]类型的对象实例, [B为byte[]类型的Java描述符,_1表示是这个类型的第一个变量,后续如果再定义了对应类型的变量则序号相应增加,如Class{[B]}_2,Class{[B]}_3等,如果是其他类型也是同样的表示方式如Class{java.lang.String}_1, Class{java.util.HashMap}_2等
上面这段代码的逻辑简单解释了创建一个byte[]数组实例,并赋值给tlab0,数组长度为ret_2 << ret_2 >>32,数组的长度之所以是ret_2 << ret_2 >> 32,是因为String计算长度时需要根据编码对数组长度进行一定的换算,大家可以查找java.lang.String.java中的相关代码。接下来即通过prepend函数将0,1还有空格都并入到tlab0,再从tlab_0中生成一个新的String对象ret_30,传递给java.io.PrintStream.write函数打印输出。其实这里还原出来的prepend函数的参数,并不是很正确,参数的位置也不正确,这也是后面需要再完善的一个地方。
两行的Java代码转换成实际的执行逻辑之后,还是比较复杂的,后续可以在目前已还原代码的基础上通过分析整合为简化的模式。
继续往下走
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
对应的是
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44为我们输入给程序的参数,即为count,count只有>=3才会执行Java代码中的for循环,这里将for循环还原为while循环,本质上语义是一质的,在while循环之外,程序代码执行了count=3的逻辑,如果count<=3,程序即执行完成,不会再进入while循环,这可能也是GraalVM在编译时做得一个优化。
我们再看下循环的跳出条件
if(sp_0x44<=rcx)
{
break
}
此处即对应了
i < count
同时rcx在每次循环过程中也在累加
sp_0x34 = rcx
rcx = sp_0x34+1
即对应了
++i
接下来,我们看看循环体中关于数值相加的逻辑如何在还原后的代码中体现,原始代码为
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
还原后的代码为
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
循环体中的其他代码即跟前面一样执行字符串相加与输出操作,还原后的代码基本体现了原代码的执行逻辑。
还需要进一步完善的地方
目前这个工具已能够基本还原程序控制流,实现一定程度的数据流分析与函数名称还原,要成为一个完善可用的工具,还需要完成下面几点:
-
较为准确的函数名称、函数参数、函数返回值还原
-
较为准确的对象信息与字段的还原
-
较为准确的表达式与对象类型推断
-
语句整合与简化
关于二进制保护的思考
本项目的目的在于探讨NativeImage逆向还原的可行性,从目前的成果来看,NativeImage的逆向还原是可行的,这也给代码保护带来了更高的挑战,许多的开发者认为,将软件编译为二进制即可高枕无忧了,而忽略了对二进制代码的保护。对于C/C++编写的软件,目前许多工具,比如IDA已经有了非常好的还原效果,甚至暴露程度不低于Java程序,笔者甚至看到有些以二进制形式发行的软件,连函数名称的符号信息都不去除,此种情况下无异于裸奔。
任何的代码都是由逻辑组成,只要其包含逻辑,就有可能通过逆向的手段还原其逻辑,只不过在于还原难度的差别而已,而代码保护工作就是尽最大程度是加大这种还原的难度。
最后,在此求个关注,这是本公众号的第一篇文章,大家如果觉得文章内容有价值,欢迎转发关注。后续将努力为大家奉献关于程序开发、逆向保护、网络安全等方面有价值的内容,与大家共同交流学习,谢谢!